GRAPE Method
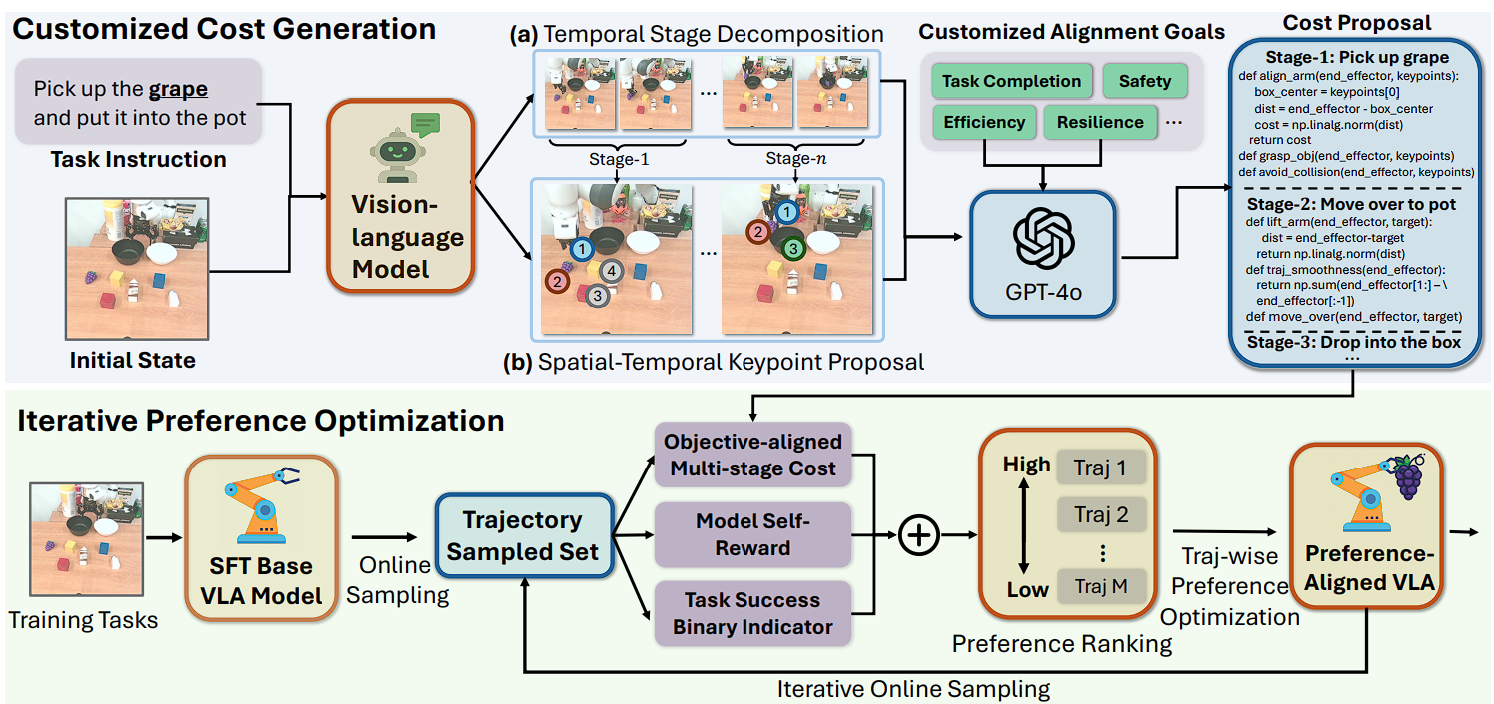
Overview of GRAPE. Given a complex manipulation task (top), GRAPE first adopts a vision-language model to decompose the task into several temporal stages, then identifies spatial keypoints essential for each stage’s subtask completion. Then given user-specified alignment goals, GRAPE prompts a powerful vision-language model to obtain a series of cost functions for each stage, where lower cost implies higher alignment compliance. During iterative preference optimization (bottom), we sample multiple offline trajectories from the base VLA model and obtain trajectories with associated multi-stage costs. This score further incorporates the model’s self-evaluation of each trajectory and a binary task success indicator. Then we rank the sampled trajectories with their corresponding scores to obtain a list of preferences. Then we perform a trajectory-wise preference optimization to obtain a improved model, from which we further sample online trajectories and iterate until convergence.